
You can cook food in a microwave in minutes. But we don’t say that microwaves “democratized” cooking.
Preparing a meal requires much more: selecting and preparing ingredients, optimizing the cooking method, and creating the right ambiance. The microwave just accelerates one part of the process.
Just as microwaves don’t handle the entire meal, automated machine learning (AutoML) only addresses a small portion of data scientists’ workflows. AutoML has become powerful and convenient. It’s a crucial step in the journey toward democratizing data science. However, there’s much more required to make data science accessible to all data professionals.
To truly democratize data science, we need to adopt automation across the entire data science workflow. Every step deserves to be addressed with robust, reliable automated tools that data analysts and business teams can use. Only then will we unlock the benefits of data science for all businesses.
What AutoML Does — and Why It’s Not Enough
AutoML typically handles model selection and hyperparameter tuning. A data professional using AutoML doesn’t need in-depth knowledge of algorithms and their use. Instead, an open-source AutoML library or a data science platform handles that part of the data science process. AutoML has become more accepted and trusted in recent years.
But successful data science involves more than modeling. According to Anaconda’s latest State of Data Science report, model selection and training account for just 18% of data scientists’ time. In the meantime, they’re spending 47% of their time on data prep, cleansing, and deployment — tasks outside the scope of AutoML tools.
To be sure, AutoML is crucial to making data science more accessible. But if that’s the goal, why isn’t there more effort to automate these other time-consuming, critical tasks?
Data Science’s Obsession With Modeling
The data science field has primarily focused on innovating with models. So far, automation has had that same narrow scope, mainly addressing model selection and hyperparameter optimization. Simply put, we’re obsessed with models.
There are a few likely reasons for this fixation. First, data scientists love the intellectual challenge of modeling, which is the mathematical heart of data science. Mastery of algorithms also creates a high bar to entering the profession that preserves data scientists’ distinctive role and elite status. But that barrier doesn’t serve businesses’ interests.
Furthermore, data science research has focused on developing new models and refining modeling strategies. As I’ve discussed elsewhere, innovations in modeling have revolved around natural language processing and computer vision, using more accessible datasets. However, tabular data — the form of most business data — has been neglected in research. New strategies for handling tabular data in the data science workflow could make a much broader impact, especially with automation.
Finally, the modeling obsession may stem from a belief that models are the only “universal” components of data science projects. In reality, as I’ll explore next, there’s more universality within data science projects than is usually assumed. That means there’s far more room for innovative automation to accelerate work on those universal elements.
Automating the Rest of the Data Science Process
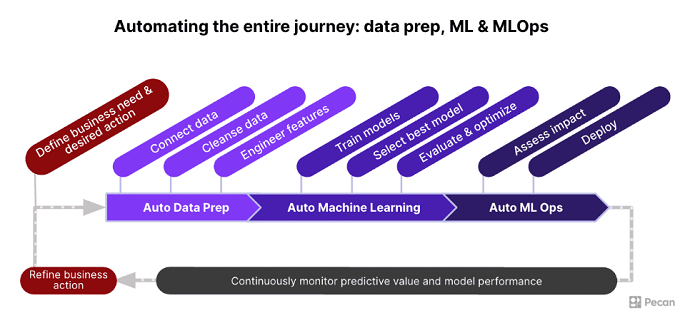
To truly democratize data science, we need to automate more than modeling. We need to explore and acknowledge other universal components of the data science workflow and then automate them wherever possible.
As we’ve discovered at Pecan (the AI company I co-founded), different companies carry out data science in similar ways. That starts with the fundamental questions they explore. Across the board, business teams tend to ask the same kinds of questions of their data. Which customers will likely churn in the next X days — and why? Who among our new customers will become a high-value customer or VIP? How can we personalize offers by anticipating which customers will be most likely to upgrade their services or buy complementary products? With these kinds of common concerns, we can standardize many questions and answer them successfully with automated methods that achieve remarkable business impact.
Not only are many businesses’ questions similar, but we also have found that their datasets relevant to those questions contain more commonalities than you might think. Companies tend to use the same kinds of data to address comparable challenges. Those similarities mean we can systematize and automate most data preparation and feature engineering.
With the right data for those recurring business questions, innovative tools can automatically identify and fix common data problems. Then, automated techniques can generate hundreds or thousands of features, transforming data in ways relevant to the business question. This automated approach casts a much wider net than selecting a few hand-crafted features and eliminates the impact of human biases on feature engineering and selection. Feature selection processes can then identify the most informative features and eliminate those that are less useful to prevent model overfitting and provide better model explainability.
With fully prepared data in hand, it’s time for modeling. Typically, it’s only at this stage that automation makes an appearance with AutoML. But AutoML provides better results with thoroughly prepared data. Savvy data scientists adopting the increasingly popular data-centric approach to AI recognize that better-prepared data improves model performance more than endless tinkering with the models themselves.
Finally, model deployment must progress beyond today’s engineering-intensive approach. It’s widely acknowledged that few models successfully move into production. Anaconda’s survey data reveals the top barriers to deployment: IT/information security concerns, data connectivity, re-coding models from Python or R into other languages, and managing packages and dependencies.
Making deployment secure and as seamless as possible can be accomplished by building connectors that feed models’ output into other business systems, as well as by automating model monitoring when models are in production. Model monitoring is critical, especially to watch for concept drift, which occurs when the target variable or outcome predicted by a model changes over time. Models need monitoring and maintenance for ongoing high performance. When handled manually, this process can be time-consuming, and it’s often neglected as a result. But fortunately, it’s now possible to automate model monitoring. Automating model deployment and monitoring helps make data scientists’ work useful and rewarding over the long term.
Achieving True Data Science Democratization
AutoML is integral to automating and democratizing data science. But on its own, it contends with just one step of a more complex undertaking.
It’s tempting to celebrate the artisanship of a manual data science workflow. And with some use cases, a hand-coded approach is absolutely required. But we must acknowledge that other parts of data science work not only can but must be automated if data science’s benefits are to be realized more broadly in business.
Even today, it’s already possible to automate the data science process as it’s applied most often to typical business challenges. The widespread nature of these challenges also means there’s incredible potential to take business outcomes to new heights with the broader adoption of automated data science.
Embracing automation beyond AutoML will make data science truly accessible to all data professionals. Only then can all businesses realize the transformative benefits of democratized data science.
About the Author

Noam Brezis is the co-founder and CTO of Pecan AI, the leader in AI-based predictive analytics for business teams and the BI analysts who support them. Pecan enables companies to harness the full power of AI and predictive modeling without requiring any data scientists or data engineers on staff. Noam holds a PhD in computational neuroscience, an MS in cognitive psychology, and a BA in economics and psychology, all from Tel Aviv University.
Sign up for the free insideAI News newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideAI NewsNOW



Speak Your Mind