
In this special guest feature, DeVaris Brown, CEO and co-founder of Meroxa, details some best practices implemented to solve data-driven decision-making problems themed around Centralized Data, Decentralized Consumption. Meroxa is a VC-backed stream processing application platform as a service that empowers developers to build data products by using their existing infrastructure, tooling, and workflows. Prior to founding Meroxa, DeVaris was a product leader at Twitter, Heroku, VSCO, and Zendesk. When he’s not sitting in front of a computer, you can find DeVaris behind a camera capturing moments in time, at the stove whipping up the finest delicacies, or behind a set of turntables, moving a sea of people through music.
The Current Data Landscape
Data-driven decision-making is becoming increasingly difficult. Data is often overwhelming, duplicated, and decentralized; the infrastructure that ingests, transforms, orchestrates, and distributes the data is fragmented, complex, and expensive; the people that organize the data are often disconnected from the needs of the business and spread across disparate teams.
In this piece, I will detail some best practices we’ve implemented in the past to solve this problem themed around Centralized Data, Decentralized Consumption. We’ll start by looking at the problems, why the current solutions fail, what Centralized Data, Decentralized Consumption looks like in practice, and finally, how it can solve many of our foundational data problems.
First, let’s look at the problem in detail.
The Data Problem
Nearly every organization needs solutions and answers from its data. A goal of nearly every data-driven organization is to:
Empower the people closest to the problem with the tools to answer their own questions.
However, the problem is these people need access to—and confidence in—the data to answer these questions. And often the teams that need the answers the most are the farthest away from the actual data. When they see the data, it is fragmented and duplicated, tools are complex and disparate, and confidence in the answers is low.
In a typical scenario, one team produces the data, while another team ingests it. This data is passed to another team to build the analytics. The analytics operations and data are handed off to data analysts, who will then play with and copy the data. Finally (and quite some time later), the sales team gets its hands on the results and finds the answers it needs.
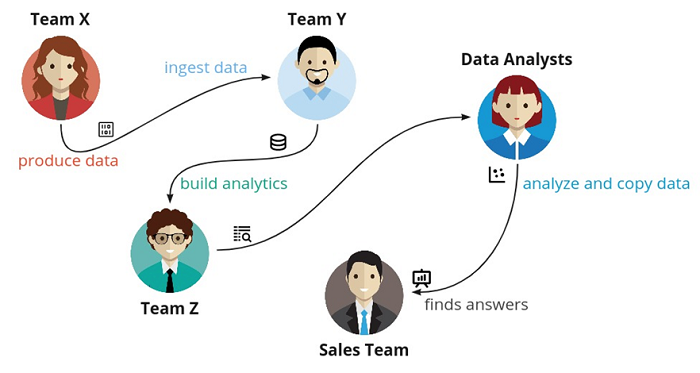
Unfortunately, this sort of data flow and process repeats itself time and time again in many organizations—even those that claim to be data-driven.
Limitations of the Current Approach
To solve this problem, many companies have implemented self-service data solutions—tools and processes designed to help users access the data answers independently. However, self-service is difficult to implement, given tool sprawl and governing required access.
Others have looked for answers by moving to data lakes and lake houses. However, most data teams still find themselves managing a large number of complex tools spanning various needs of the entire data lifecycle:
- Analytics tools
- Data governance
- Master data management (MDM)
- Warehousing
- Data quality
- Alerting
- Orchestration
- Data transformation
- … and many more.
Users don’t know where the data came from, what it’s really for, and if it can be trusted. In addition, they often have multiple copies of the same information.
The cost and complexity of managing such a large set of data tooling and processes are only part of the problem. A more serious set of questions arise when we apply business principles and practices to this flow. For example, who truly owns the data at each step? And what is the true source of the data? In our example above, there are so many sources of this data in this flow that the data lake or data warehouse is no longer a meaningful or trustworthy source of truth.
Our problem remains: How can data practitioners provide a single, reliable source of data to various business functions to answer immediate questions?
A New Approach: Centralized Data, Decentralized Consumption (CDDC)
A new concept has recently risen in addressing these issues: centralized data, decentralized consumption.
Let’s look at what that means by breaking down the idea into two main points:
- An organization centralizes the data, processes, and policies by standardizing the following:
- What data is collected
- What data is offered
- How data is offered
- Where data is consumed
- At the same time, the organization decentralizes the consumption of that data.
On the surface, CDDC may appear to be an implementation of a data mesh, but there’s a tad more nuance. In the data mesh, the responsibility of creating a data product is done by the domain owner. They access the firehose and transform the data into their specific use case. Our CDDC approach takes this a step further by being extremely intentional about the data that enters the firehose before it reaches the domain owner so they can have more confidence in the data products they build.
Centralized Data in Practice
Enough theory talk. What does this look like in practice? It’s a mix of people, process, and platform. Below are some of the foundational best practices:
- You need to have a dedicated product manager or tech lead that’s responsible for the centralized data platform. Their job is to understand stakeholder requirements and ensure that the incoming data is in an easily understandable and consumable format for self service.
- Establish a culture of creating and using data contracts in feature teams. This can be a separate post on its own but here are articles that give some more background on what data contracts are and how to implement them.
- Use change data capture (CDC) for data ingestion and stream processing to normalize the shape of the data for self-service consumption. Never consume the raw CDC stream to build data products.
- Leverage testing and observability to catch breaking changes in the schema and data contract.
- Document everything – It doesn’t matter if it’s a data catalog, spreadsheet, or text document, producers and consumers of the data need a canonical place to understand the end to end data landscape.
Advantages of Centralized Data, Decentralized Consumption
This new CDDC flow has several advantages:
- Consumers of this data can trust the data assets in a way that has not been possible before. They know the data will be clean and in a certain format.
- The distribution of the data is consistent and controlled. Consumers can now answer their own questions effectively and efficiently.
- The result is better business outcomes and more innovation.
Conclusion
It’s clear that today’s data landscape is experiencing an overabundance of tooling, complex architecture, increasing costs, complicated data teams, fragmented datasets, and sporadic data policies and controls.
To combat these issues, the idea of centralized data and decentralized consumption has become an important concept that addresses not only the logical and physical problems of dealing with complex data, but the approach and use of business policies and processes used to handle the datasets.
Sign up for the free insideAI News newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideAI NewsNOW



Speak Your Mind