
Achieve 50% Sparsity With One-Shot Learning Without Any Retraining
It might come as a surprise, but large language models are a great match for sparsification. Why? They give up less accuracy as compared to the amount of weights that are being eliminated (set to 0). This is an encouraging finding from Neural Magic‘s collaboration with the Institute of Science and Technology Austria (ISTA) because it makes it possible to run billion parameter models more efficiently, with significantly less hardware.
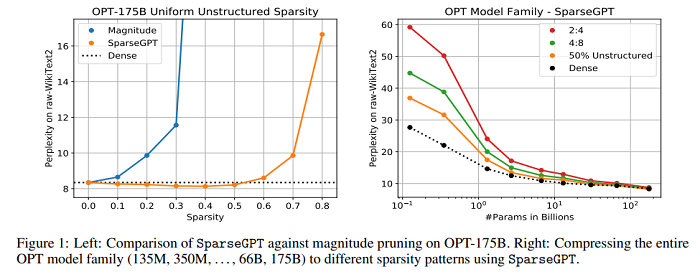
A new research paper shows that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy. This is achieved via a new pruning method called SparseGPT, specifically designed to work efficiently and accurately on massive GPT-family models. When executing SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, we can reach 60% sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time. SparseGPT generalizes to semi-structured (2:4 and 4:8) patterns, and is compatible with weight quantization approaches.
Sign up for the free insideAI News newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideAI NewsNOW



Speak Your Mind