Impetus Technologies, a big data software products and services company, announced the immediate availability of Visual Spark StudioTM, a new standalone tool aimed at addressing the increasing demand for Spark-based analytic and data processing solutions in enterprises.
Impetus Technologies Delivers Visual Spark Studio – A New, Free Development Tool to Accelerate Spark Adoption in Enterprises
September 28, 2017 by Leave a Comment
Interview: Ash Munshi, CEO at Pepperdata
August 4, 2017 by Leave a Comment

I recently caught up with Ash Munshi, CEO at Pepperdata, to get a rundown on his company, a sense for how big data and DevOps are related, some highlights on new product offerings, and his sense for where Pepperdata is headed in the future.
IBM Combines All-Flash and Storage Software Optimized for Hortonworks
July 31, 2017 by Leave a Comment
IBM (NYSE: IBM) announced a new all-flash, high-performance data and file management solution for enterprise clients running exabyte-scale big data analytics, cognitive and AI applications. The combined flash and storage software solution has been certified with the Hortonworks Data Platform (HDP) to provide clients with more choice in selecting the right platform for their big data analytics on data processing engines like Hadoop and Spark.
Unravel Data Adds Native Support for Impala and Kafka
June 29, 2017 by Leave a Comment
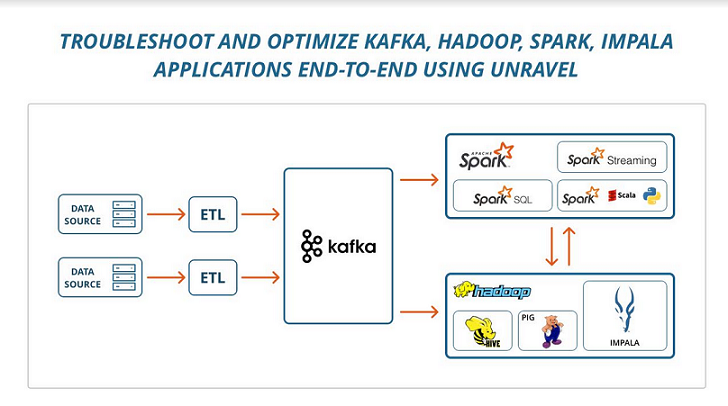
Unravel Data, the Application Performance Management (APM) platform designed for Big Data, announced that it has integrated support for Cloudera Impala and Apache Kafka into its platform, allowing users to derive the maximum value from those applications. Unravel continues to offer the only full-stack solution that doesn’t just monitor and unify system-level data, but rather tracks, correlates, and interprets performance data across the full-stack in order to optimize, troubleshoot, and analyze from a single pane.
Databricks Simplifies and Scales Deep Learning with New Apache Spark Library
June 7, 2017 by Leave a Comment
Databricks, the company founded by the creators of the popular Apache Spark project, announced Deep Learning Pipelines, a new library to integrate and scale out deep learning in Apache Spark.
The Definitive Guide to Evaluating Cloud-based Apache Spark Platforms
June 5, 2017 by Leave a Comment

This guide is designed to help you focus on your overall company goals. Do you want to build and manage your own Spark environment or leverage the best possible choice on the market? Find a solution you can use as an effective tool for the real work of getting business value from big data analytics. To learn more download this definitive guide to evaluating cloud-based Apache Spark platforms.
Cloudera Launches Altus to Simplify Big Data Workloads in the Cloud
May 27, 2017 by Leave a Comment
Cloudera, Inc, (NYSE:CLDR) the provider of a leading modern platform for machine learning and advanced analytics, announced the release of Cloudera Altus, a Platform-as-a-Service (PaaS) offering that makes it easier to run large-scale data processing applications on public cloud.
Hadoop, Spark or Both?
May 26, 2017 by 1 Comment

In this contributed article, tech writer Blake Davies asks the question: Spark or Hadoop? This question has recently sparked various discussions throughout the online communities. Even though these two work on different principles, they can be applied in a same way for various uses. While Hadoop is a household name in the world of big data processing, Spark is still building a name for itself and it’s doing so with “style”.
Pepperdata® Code Analyzer for Apache Spark Highlights Performance Bottlenecks for Developers
May 25, 2017 by 1 Comment
Pepperdata, the DevOps for Big Data company, announced Pepperdata Code Analyzer for Apache Spark, which provides Spark application developers the ability to identify performance issues and connect them to particular blocks of code within an application. Code Analyzer is a new product that follows on the heels of Pepperdata Application Profiler, which provides Hadoop and Spark developers with actionable recommendations for improving job performance.
MapR Releases New Ecosystem Pack with Optimized Security and Performance for Apache Spark
May 23, 2017 by Leave a Comment
MapR Technologies, Inc., the provider of the Converged Data Platform that converges the essential data management and application processing technologies on a single, horizontally scalable platform, announced its next major release of the MapR Ecosystem Pack (MEP) program. MEP is a broad set of open source ecosystem projects that enable big data applications running on the MapR Converged Data Platform with inter-project compatibility.


