
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Learning with Multiclass AUC: Theory and Algorithms
The Area under the ROC curve (AUC) is a well-known ranking metric for problems such as imbalanced learning and recommender systems. The vast majority of existing AUC-optimization-based machine learning methods only focus on binary-class cases, while leaving the multiclass cases unconsidered. This paper starts an early trial to consider the problem of learning multiclass scoring functions via optimizing multiclass AUC metrics. Our foundation is based on the M metric, which is a well-known multiclass extension of AUC. The paper pays a revisit to this metric, showing that it could eliminate the imbalance issue from the minority class pairs. Motivated by this, it is proposec an empirical surrogate risk minimization framework to approximately optimize the M metric. Theoretically, it is shown that: (i) optimizing most of the popular differentiable surrogate losses suffices to reach the Bayes optimal scoring function asymptotically; (ii) the training framework enjoys an imbalance-aware generalization error bound, which pays more attention to the bottleneck samples of minority classes compared with the traditional O(√(1/N)) result. Practically, to deal with the low scalability of the computational operations, acceleration methods are proposed for three popular surrogate loss functions, including the exponential loss, squared loss, and hinge loss, to speed up loss and gradient evaluations. Finally, experimental results on 11 real-world datasets demonstrate the effectiveness of our proposed framework.
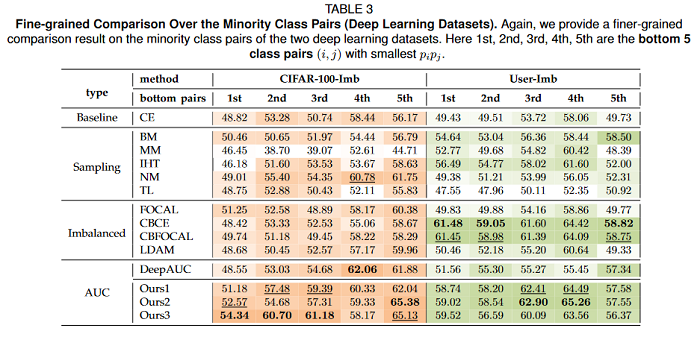
Evaluating Large Language Models Trained on Code
This paper introduces Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set released to measure functional correctness for synthesizing programs from docstrings, the model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, 70.2% of problems are solved with 100 samples per problem. Careful investigation of the model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics is discussed.
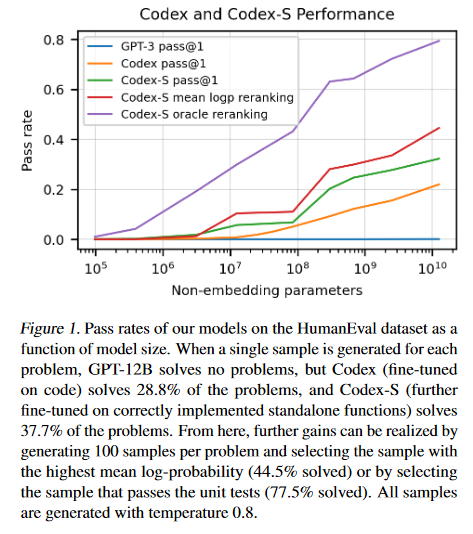
A Generalized Lottery Ticket Hypothesis
This paper introduces a generalization to the lottery ticket hypothesis in which the notion of “sparsity” is relaxed by choosing an arbitrary basis in the space of parameters. Evidence is presented that the original results reported for the canonical basis continue to hold in this broader setting. Structured pruning methods are described, including pruning units or factorizing fully-connected layers into products of low-rank matrices, can be cast as particular instances of this “generalized” lottery ticket hypothesis.
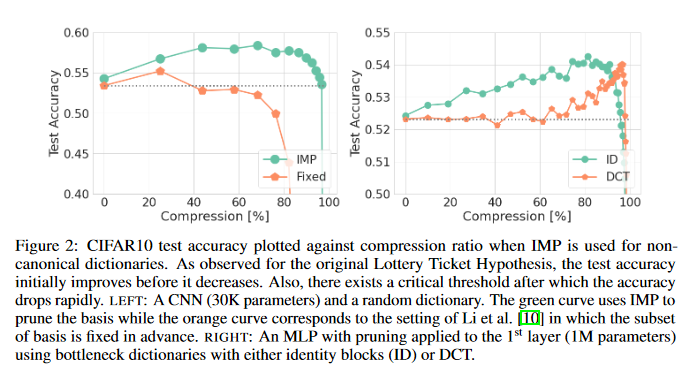
YOLOX: Exceeding YOLO Series in 2021
This paper presents some experienced improvements to YOLO series, forming a new high-performance detector — YOLOX. The YOLO detector is switched to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, 25.3% AP on COCO is found, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, and is boosted to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, 50.0% AP on COCO is achieved at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. The GitHub repo associated with this paper can be found HERE.
CBNetV2: A Composite Backbone Network Architecture for Object Detection
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. This paper proposes a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. Also proposed is a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). The GitHub repo associated with this paper can be found HERE.
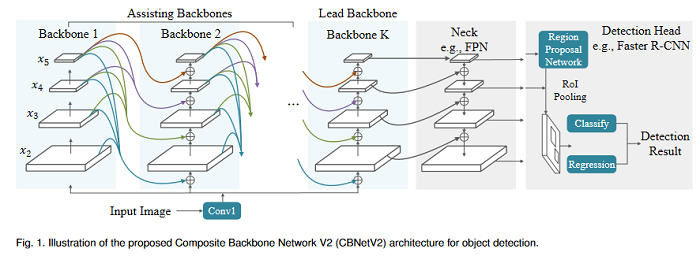
Global Filter Networks for Image Classification
Recent advances in self-attention and pure multi-layer perceptrons (MLP) models for vision have shown great potential in achieving promising performance with fewer inductive biases. These models are generally based on learning interaction among spatial locations from raw data. The complexity of self-attention and MLP grows quadratically as the image size increases, which makes these models hard to scale up when high-resolution features are requiring. This paper presents the Global Filter Network (GFNet), a conceptually simple yet computationally efficient architecture, that learns long-term spatial dependencies in the frequency domain with log-linear complexity. The architecture replaces the self-attention layer in vision transformers with three key operations: a 2D discrete Fourier transform, an element-wise multiplication between frequency-domain features and learnable global filters, and a 2D inverse Fourier transform. Favorable accuracy/complexity trade-offs of the models on both ImageNet and downstream tasks are exhibited. The results demonstrate that GFNet can be a very competitive alternative to transformer-style models and CNNs in efficiency, generalization ability and robustness. The GitHub repo associated with this paper can be found HERE.
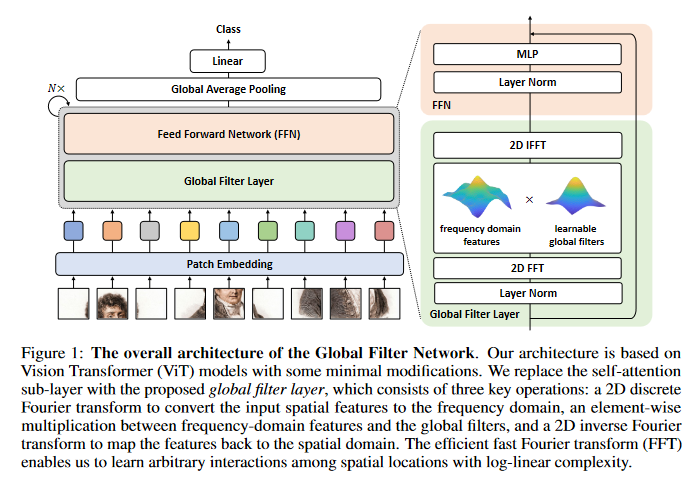
Perceiver IO: A General Architecture for Structured Inputs & Outputs
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original’s appealing properties by learning to flexibly query the model’s latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation. The GitHub repo associated with this paper can be found HERE.
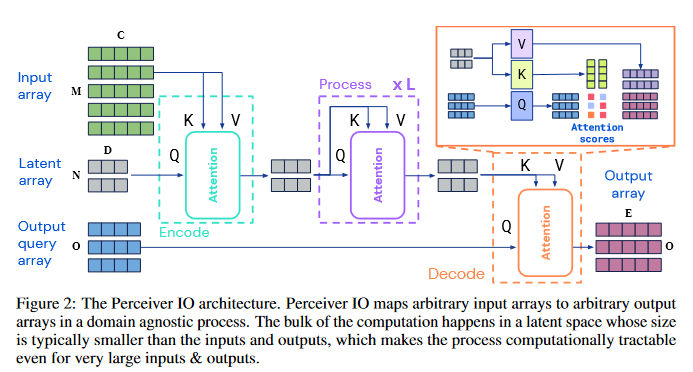
Resisting Out-of-Distribution Data Problem in Perturbation of XAI
With the rapid development of eXplainable Artificial Intelligence (XAI), perturbation-based XAI algorithms have become quite popular due to their effectiveness and ease of implementation. The vast majority of perturbation-based XAI techniques face the challenge of Out-of-Distribution (OoD) data – an artifact of randomly perturbed data becoming inconsistent with the original dataset. OoD data leads to the over-confidence problem in model predictions, making the existing XAI approaches unreliable. The OoD data problem in perturbation-based XAI algorithms has not been adequately addressed in the literature. This paper addresses this OoD data problem by designing an additional module quantifying the affinity between the perturbed data and the original dataset distribution, which is integrated into the process of aggregation. The solution is shown to be compatible with the most popular perturbation-based XAI algorithms, such as RISE, OCCLUSION, and LIME. Experiments have confirmed that the proposed methods demonstrate a significant improvement in general cases using both computational and cognitive metrics.
LocalGLMnet: interpretable deep learning for tabular data
Deep learning models have gained great popularity in statistical modeling because they lead to very competitive regression models, often outperforming classical statistical models such as generalized linear models. The disadvantage of deep learning models is that their solutions are difficult to interpret and explain, and variable selection is not easily possible because deep learning models solve feature engineering and variable selection internally in a nontransparent way. Inspired by the appealing structure of generalized linear models, this paper proposes a new network architecture that shares similar features as generalized linear models, but provides superior predictive power benefiting from the art of representation learning. This new architecture allows for variable selection of tabular data and for interpretation of the calibrated deep learning model, in fact, the approach provides an additive decomposition in the spirit of Shapley values and integrated gradients.
Sign up for the free insideAI News newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind