
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Understanding and Avoiding AI Failures: A Practical Guide
As AI technologies increase in capability and ubiquity, AI accidents are becoming more common. Based on normal accident theory, high reliability theory, and open systems theory, this paper creates a framework for understanding the risks associated with AI applications. In addition, the researchers also use AI safety principles to quantify the unique risks of increased intelligence and human-like qualities in AI. Together, these two fields give a more complete picture of the risks of contemporary AI. By focusing on system properties near accidents instead of seeking a root cause of accidents, the paper identifies where attention should be paid to safety for current generation AI systems.
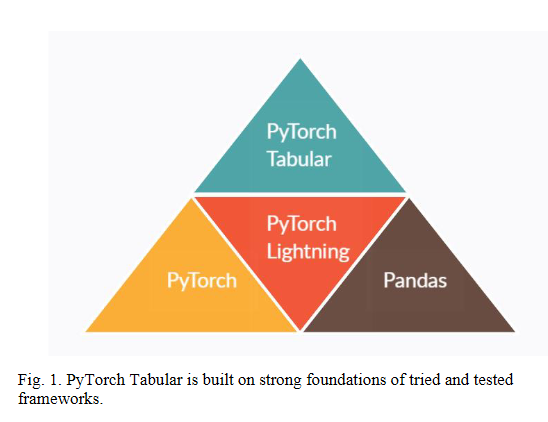
PyTorch Tabular: A Framework for Deep Learning with Tabular Data

In spite of showing unreasonable effectiveness in modalities like Text and Image, Deep Learning has always lagged Gradient Boosting in tabular data – both in popularity and performance. But recently there have been newer models created specifically for tabular data, which is pushing the performance bar. But popularity is still a challenge because there is no easy, ready-to-use library like Sci-Kit Learn for deep learning. PyTorch Tabular is a new deep learning library which makes working with Deep Learning and tabular data easy and fast. It is a library built on top of PyTorch and PyTorch Lightning and works on pandas dataframes directly. Many SOTA models like NODE and TabNet are already integrated and implemented in the library with a unified API. PyTorch Tabular is designed to be easily extensible for researchers, simple for practitioners, and robust in industrial deployments.
Generative Adversarial Network: Some Analytical Perspectives
Ever since its debut, generative adversarial networks (GANs) have attracted tremendous amount of attention. Over the past years, different variations of GANs models have been developed and tailored to different applications in practice. Meanwhile, some issues regarding the performance and training of GANs have been noticed and investigated from various theoretical perspectives. This paper will start from an introduction of GANs from an analytical perspective, then move on the training of GANs via SDE approximations and finally discuss some applications of GANs in computing high dimensional MFGs as well as tackling mathematical finance problems.

Exploring Bayesian Deep Learning for Urgent Instructor Intervention Need in MOOC Forums
Massive Open Online Courses (MOOCs) have become a popular choice for e-learning thanks to their great flexibility. However, due to large numbers of learners and their diverse backgrounds, it is taxing to offer real-time support. Learners may post their feelings of confusion and struggle in the respective MOOC forums, but with the large volume of posts and high workloads for MOOC instructors, it is unlikely that the instructors can identify all learners requiring intervention. This problem has been studied as a Natural Language Processing (NLP) problem recently, and is known to be challenging, due to the imbalance of the data and the complex nature of the task. In this paper, we explore for the first time Bayesian deep learning on learner-based text posts with two methods: Monte Carlo Dropout and Variational Inference, as a new solution to assessing the need of instructor interventions for a learner’s post. This paper compares models based on proposed methods with probabilistic modelling to its baseline non-Bayesian models under similar circumstances, for different cases of applying prediction. The results suggest that Bayesian deep learning offers a critical uncertainty measure that is not supplied by traditional neural networks. This adds more explainability, trust and robustness to AI, which is crucial in education-based applications.
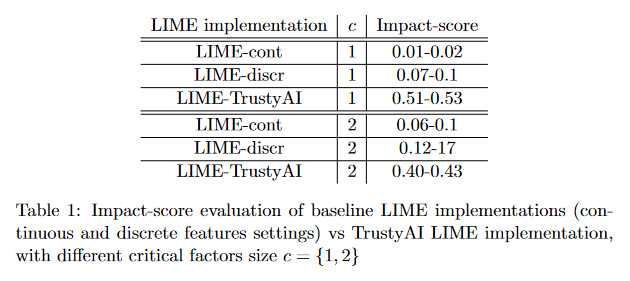
TrustyAI Explainability Toolkit
Artificial intelligence (AI) is becoming increasingly more popular and can be found in workplaces and homes around the world. However, how do we ensure trust in these systems? Regulation changes such as the GDPR mean that users have a right to understand how their data has been processed as well as saved. Therefore if, for example, you are denied a loan you have the right to ask why. This can be hard if the method for working this out uses “black box” machine learning techniques such as neural networks. TrustyAI is a new initiative which looks into explainable artificial intelligence (XAI) solutions to address trustworthiness in ML as well as decision services landscapes. This paper looks at how TrustyAI can support trust in decision services and predictive models. We investigate techniques such as LIME, SHAP and counterfactuals, benchmarking both LIME and counterfactual techniques against existing implementations.
A Short Survey of Pre-trained Language Models for Conversational AI-A NewAge in NLP
Building a dialogue system that can communicate naturally with humans is a challenging yet interesting problem of agent-based computing. The rapid growth in this area is usually hindered by the long-standing problem of data scarcity as these systems are expected to learn syntax, grammar, decision making, and reasoning from insufficient amounts of task-specific dataset. The recently introduced pre-trained language models have the potential to address the issue of data scarcity and bring considerable advantages by generating contextualized word embeddings. These models are considered counterpart of ImageNet in NLP and have demonstrated to capture different facets of language such as hierarchical relations, long-term dependency, and sentiment. This short survey paper discusses the recent progress made in the field of pre-trained language models.
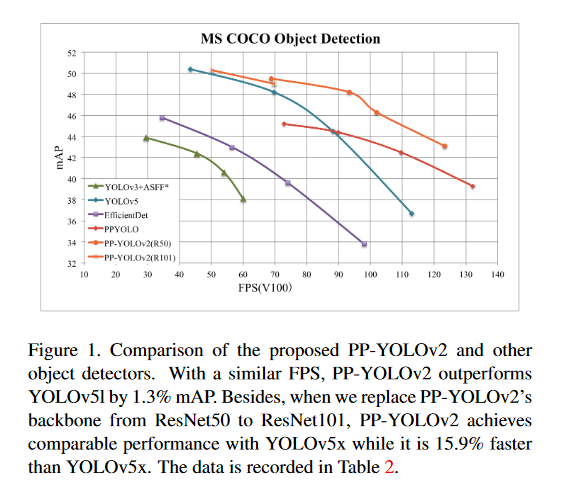
PP-YOLOv2: A Practical Object Detector
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, this paper comprehensively evaluates a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. The paper analyzes a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things tried that didn’t work will also be discussed. Source code associated wit this paper can be found HERE.
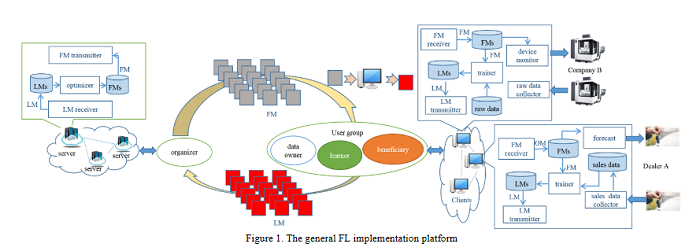
A Survey on Federated Learning and its Applications for Accelerating Industrial Internet of Things
Federated learning (FL) brings collaborative intelligence into industries without centralized training data to accelerate the process of Industry 4.0 on the edge computing level. FL solves the dilemma in which enterprises wish to make the use of data intelligence with security concerns. To accelerate industrial Internet of things with the further leverage of FL, existing achievements on FL are developed from three aspects: 1) define terminologies and elaborate a general framework of FL for accommodating various scenarios; 2) discuss the state-of-the-art of FL on fundamental researches including data partitioning, privacy preservation, model optimization, local model transportation, personalization, motivation mechanism, platform tools, and benchmark; 3) discuss the impacts of FL from the economic perspective. To attract more attention from industrial academia and practice, a FL-transformed manufacturing paradigm is presented in this paper, and future research directions of FL are given and possible immediate applications in Industry 4.0 domain are also proposed.
Sign up for the free insideAI News newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind