
Artificial Intelligence (AI) and Deep Learning (DL) represent some of the most demanding workloads in modern computing history as they present unique challenges to compute, storage and network resources. In this technology guide, insideAI News Guide to Optimized Storage for AI and Deep Learning Workloads, we’ll see how traditional file storage technologies and protocols like NFS restrict AI workloads of data, thus reducing the performance of applications and impeding business innovation. A state-of-the-art AI-enabled data center should work to concurrently and efficiently service the entire spectrum of activities involved in DL workflows, including data ingest, data transformation, training, inference, and model evaluation.
The intended audience for this important new technology guide includes enterprise thought leaders (CIOs, director level IT, etc.), along with data scientists and data engineers who are a seeking guidance in terms of infrastructure for AI and DL in terms of specialized hardware. The emphasis of the guide is “real world” applications, workloads, and present day challenges.
Introduction
Optimized storage has a unique opportunity to become much more than a siloed repository for the deluge of data constantly generated in today’s hyper-connected world, but rather a platform that shares and delivers data to create competitive business value. Optimized storage is designed for the needs of a broad range of problem domains including FinTech, life sciences, design, HPC, government, smart cities, media, energy, and many more.
Optimized storage solutions are faced with I/O intensive workflows found in AI. Traditional structured data infrastructure is acceptable in many cases, whereas an optimized storage platform is targeted at other classes of problems that tend to be unstructured and throughput intensive.
Today, we’re seeing an emphasis for rebalancing the cloud. AI is bucking the trend toward migration to the cloud. By their nature, some enterprises generate a lot of unstructured data at the edge, e.g. in a vehicle, in a store, from a microscope in a lab. These use cases are very non-cloud-friendly since there is a need to ingest a large amount of data. With technologies
like 5G and IoT, it’s important to do real-time analytics on that data. This means huge data volumes come into play, and real-time analytics is changing what was previously seen as a homogeneous move of everything to the cloud. That emphasis is being stopped in its tracks now, and there is much more of an equilibrium state of edge and on-prem gains with a change in IT thinking these days. It’s not just an “all cloud” story, but a more complex narrative.
How Optimized Storage Solves AI Challenges
The IT infrastructure supporting an AI-enabled data center must adapt and scale rapidly, efficiently and consistently as data volumes grow and application workloads become more intense, complex and diverse. The nature of DL deployments means IT resources must seamlessly and continuously handle transitions between different phases of experimental training and production inference in order to provide faster and more accurate answers. In short, the IT infrastructure is instrumental to realizing the full potential of AI and DL in business and research.
Yet as demand continues to rise, current enterprise and research data center IT infrastructures are sadly inadequate in handling the challenging needs of AI and DL. Designed to handle modest workloads, minimal scalability, limited performance needs and small data volumes, these platforms are highly bottlenecked and lack the essential capabilities required for AI-enabled deployments.
Data storage is a central area of focus. There are a number of easily identified differences between traditional storage and optimized AI data
platforms. For example, challenges with traditional storage include: low speed, poor latency, no graphics processing unit (GPU) integration, no
container optimization, limited scaling, no multiple writers, and inefficient TCP/IP communication. In contrast, AI data platform benefits include: fully
saturates GPU/CPU, maximizes efficiency at scale, continuous data availability, highest deep learning acceleration, seamless scalability, effortless deployment and management.
Optimized storage platforms for AI and DL workloads offer support for a broad range of uses cases in the following ways:
- Accelerate applications by achieving full GPU saturation
- Streamline concurrent and continuous DL workflows
- Flexible configuration with best technology and economics
- Seamless scaling to match evolving workflow needs
Parallel Data from Storage to GPU
Revolutionary breakthrough technologies in processors and storage serve as important catalysts for effective AI data center enablement. For example, GPUs deliver compute acceleration over slower CPUs, while Flash Enabled Parallel I/O Storage provides a significant performance boost to legacy hard disk-based storage. Specifically, GPUs are significantly more scalable
and faster than CPUs while their large number of cores permit massively parallel execution of concurrent threads. This parallelism results in
accelerated training and inference capabilities for AI/DL applications.
In order for GPUs to fulfill their promise of acceleration however, data must be processed and delivered to the underlying AI applications
with great speed, scalability and consistently low latencies. This requires a parallel I/O storage platform for performance scalability, real time data delivery, and flash media for speed. Without the right data storage platform, a GPU-based computing platform is just as bottlenecked and lacking as a traditional non-AI-enabled data center. The proper selection of the data storage platform and its efficient integration in the data center infrastructure are key factors to eliminating AI blockages and truly accelerating time-to-insight.
The right data storage system must deliver high throughput, high IOPS and high concurrency in order to prevent idling of precious GPU cycles.
It must be flexible and scalable in implementation and enable efficient handling of a wide breadth of data sizes and types, including highly concurrent random streaming, a typical DL data set attribute.
Properly selected and implemented, such a data storage system will deliver the full potential of GPU computing platforms, accelerate time-to-insight
at any scale, effortlessly handle every stage of the AI and DL process, and do so reliably, efficiently and cost effectively.
GPUs provide a powerful platform for AI. Their high number of cores deliver a massive parallel computing facility that can process very large
amounts of data simultaneously. To achieve the full potential of AI and DL applications and maximize the benefits of GPUs, data saturation of all cores must be achieved and sustained. Fulfilling this requirement for multiple GPUs simultaneously poses a significant technical challenge.
It’s necessary to provide a highly scalable shared storage platform which effortlessly integrates with multi-GPU computing environments, while
maintaining concurrent data saturation. The platform can start small while still delivering the performance needed for GPU saturation, and scale seamlessly in performance, capacity and capability. As data sets grow and additional GPUs are deployed, it’s critical to continuously deliver an optimized, extremely cost-effective solution. The parallel architecture and protocol should deliver data with high-throughput, low-latency, and massive concurrency. It should also provide increased performance for DL frameworks and offer significantly faster processing than NFS.
Optimized AI Infrastructure in Support for Real-world Applications
Many organizations have become more entrenched in running real world workloads and real world applications based on AI and DL. Here are some examples of proven ways optimized storage solves AI challenges:
- AI powered retail – deploy and manage data solutions across thousands of remote, autonomous checkouts
- Financial services – demonstrate due diligence and adherence to regulations around customer data
- Language processing – guarantee a real-time experience during peak loads
- Autonomous vehicles – manage hundreds of petabytes of globally distributed data
- Life sciences and healthcare – securely extract value from patient data in real-time
- HPC – integrate HPC with AI, and accelerate tough HPC and AI workloads
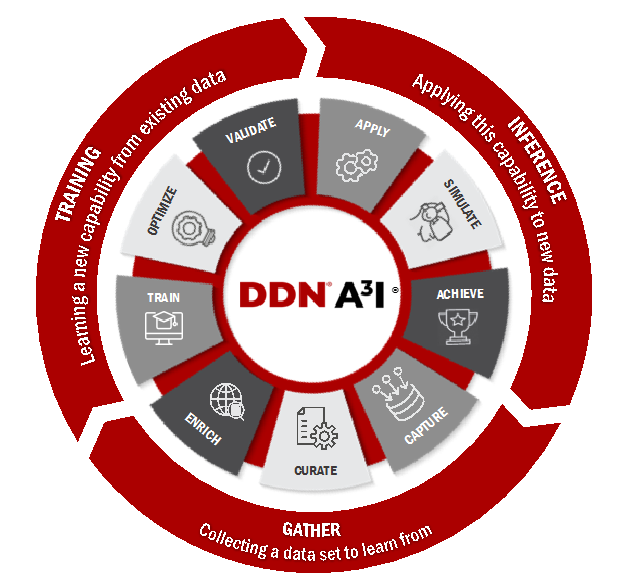
Optimized storage solutions work to effortlessly address the complete AI lifecycle as shown in the figure below. The AI workflow is fully optimized
concurrently, continuously, and in-place.
Over the next few weeks we will explore these topics surrounding data platforms for AI & deep learning:
- Introduction, How Optimized Storage Solves AI Challenges
- A³I – Accelerated, Any-scale AI Solutions
- Frameworks for AI and DL Workflows
- Partners Important Role for Leading-Edge Case Studies, Summary
If you prefer, the complete insideAI News Guide to Optimized Storage for AI and Deep Learning Workloads is available for download from the insideAI News White Paper Library, courtesy of DDN.



Speak Your Mind