
This article overviews StyleGAN2 application to image generation task and is based on MobiDev’s logotype synthesis research.
When it comes to powerful generative models for image synthesis, the most commonly mentioned are StyleGAN and its updated version StyleGAN2. These models created by Nvidia Labs are able to solve image generation tasks and produce remarkably high fidelity images of non-existent people, animals, landscapes, and other objects given an appropriate training dataset.
StyleGAN, just like the other GAN architectures, features two sub-networks: Discriminator and Generator. During the training, the Generator is tasked with producing synthetic images while the Discriminator is trained to differentiate between the fakes from Generator and the real images.
The first iteration of StyleGAN appeared in 2019. It was applied to produce fake faces with high detailization and natural appearance with resolutions up 1024×1024, not previously achieved by other similar models. However, some AI-generated faces had artifacts, so Nvidia Labs decided to improve the model and presented StyleGAN2. One of the main issues of the original StyleGAN were blob-like artifacts that looked like drops of water.


According to the StyleGAN2 paper, this problem is related to the instance normalization operation applied in AdaIN layers. The basic purpose of AdaIN is to fuse together two images: one containing style (style is a property that is present throughout all the image) and one containing the content of the image. Part of the crucial information of the inputs is being lost during this process. Why is this happening?
AdaIN works separately with the variance and mean of individual feature maps. The feature map is an intermediate representation of an image within the neural network. Feature maps carry the information regarding the image that is being generated and normalize their values.
As each feature map is normalized individually, information about the relative feature map values in regard to each other is lost in this process. As a result, the generator network produces the blob artifact with a strong signal within the image, effectively bypassing the AdaIN in an attempt to preserve the relative information that the normalization destroys.
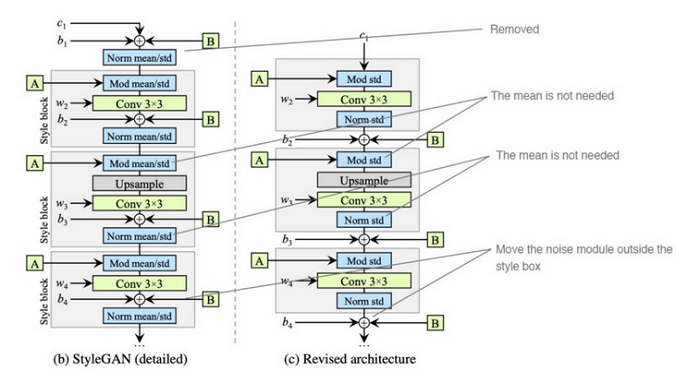
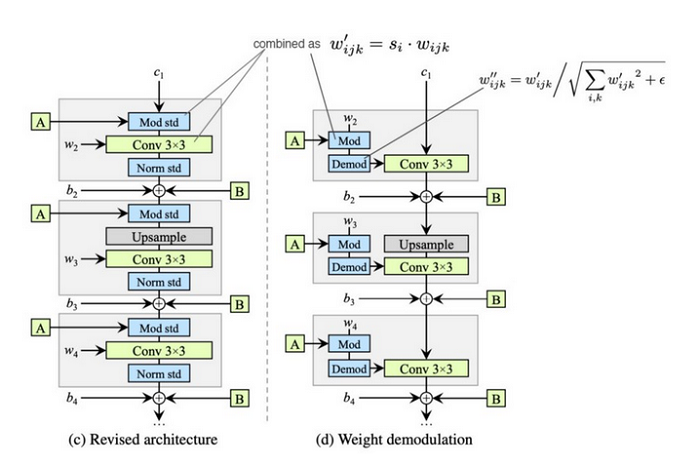
The development of StyleGAN2 was related not only to addressing the issue with AdaIN, there were other improvements in comparison with StyleGAN:
- Network redesign – small changes were made in the order and type of operations within the style blocks of the network leading to small positive improvements in the network’s performance.
- Lazy regularization – researchers found out that it is not necessary to compute regularization terms in addition to the main loss function at every training iteration. Instead, it can be computed periodically thus reducing the computational costs while having little to no effect on the quality of the results.
- Path length regularization – it was observed that uniformity of latent space W (this space is sampled from to obtain styles for image generation) had a positive effect on image quality. Uniformity was achieved by making sure that a fixed size step when sampling from W space led to a fixed size change in the generated image regardless of the direction of the step.
- Progressive growth replaced – the original architecture used progressive growing to train the model for higher resolutions (at first the model is trained to generate 8×8 images, then 16×16, and so on), however this method introduced certain artifacts in the produced images. Therefore, the authors decided to use skip connections in generator and discriminator instead, managing to avoid the aforementioned problem.
You have read about StyleGAN and StyleGAN2, but you can dive deeper into the peculiarities of architecture by getting acquainted with the next section of the article.
What’s Notable in StyleGAN Architecture?
An important differentiating feature about StyleGAN is the fact that the latent vector z is not injected into the model directly like in the traditional architectures but is instead first mapped onto a latent space which has separate vectors controlling the style of the generated image at different resolutions, from 4×4 all the way up to 1024×1024.
The influence of style vectors injected into the generator is localized using AdaIN layers (replaced with demodulation in StyleGan2), making sure one style vector affects only one convolution operation before AdaIN is applied once more. Finally, while style vectors control the overall content of the image (gender, age, hair type, skin color, etc.), randomized noise vectors add some variation into the generated image, e.g skin details, hair placement etc.

The architecture has attracted much attention. Researchers found ways to generate images better and project the real images into the latent space of the model (this task can also be called inversion). For a model that was trained on facial images, the projection process essentially results in finding synthetic doubles of the real people. When such a double is found, all manner of manipulations can be done to modify the double’s appearance.
Presumably, with the Pixel2Style2Pixel framework, StyleGAN architecture can essentially be turned into a jack-of-all-trades image editing tool. Some of the tasks it can be used for are improved inversion, face pose editing, super-resolution, facial generation from sketches, or segmentation maps, as illustrated in the Fig. 5.
Many of the features demonstrated in the developed products (e.g. face in editing in FaceApp) closely resemble the outputs of Pixel2Style2Pixel, giving us some solid grounds for assumptions about which techniques the businesses use under the hood.

Applying GANs to Logotype Synthesis
As a part of internal research in our company, we applied the StyleGAN2 architecture to a problem of logotype synthesis. We used all the recent developments and improvements introduced by researchers – adaptive discriminator augmentation, mixed-precision training, and self-attention layers. To receive GAN generated logotypes almost 49,000 images were used as a training dataset.
Text-based images were removed because generating textual logotypes requires at least three models. For instance, the language model like BERT or GPT-2 to produce synthetic logotype text, GlyphGAN model that creates characters with unique fonts to visualize the synthetic text, and a third model for generating the logotype itself.
The training dataset was aggregated into 10 clusters; this information helped the model in generating images from various logotype groups. As a result, the model was able to generate logotypes whose quality was ranging from good to medium and poor. The results were carefully analyzed to understand the reason for the model’s outputs and find the ways to improve it in the future.

The Future of GANs
The research showed that AI has a huge potential in the area of image creation. But the question remains: what else could be achieved with the help of GANs? The paper published in Nature suggests that machine learning could significantly contribute to material science as GAN architecture was found to be able to generate chemically valid hypothetical inorganic compounds. Even though the system is still missing some key components (prediction of hypothetical materials’ crystal structure, addition of strict chemical rule filters) the published results mean one day machine learning may be responsible for inventing new materials such as ultra-light durable alloys, solid state electrolytes for Li-Ion batteries, etc.
About the Author

Maksym Tatariants, PhD is an AI Engineer at MobiDev. Maksym obtained Master’s Degree in Mechanical Engineering, dealing with design of equipment for Renewable Energy applications. His engineering background helps him gain new insights and skills in applying Machine Learning, Deep Learning, and Computer Vision to technology and science projects.
Sign up for the free insideAI News newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind