LinkedIn data represents the world’s largest online professional network, with relationships among more than 467M members, 290M jobs and 9M organizations through professional entities and attributes. This data provides the foundation of consumer products for our members and monetization products for premium members. Data value is usually measured by revenue and user engagement with the products, both of which depend on the accuracy and comprehensiveness of the data. For example, the successfulness of LinkedIn Sales Navigator is determined by how accurately it finds the right decision makers in a company for salespeople to contact, and how many such candidates are discovered.
Knowledge derived from LinkedIn data needs to be represented without ambiguity in a machine-legible way. The LinkedIn Knowledge Graph standardizes entities and relationships by forming the ontology of the professional world on top of entity taxonomies, which define the identity and attributes of each entity and the relationships among the entities. Compared to the raw data inputted by members, the LinkedIn Knowledge Graph fundamentally improves the quality of knowledge representation. To improve the quality of knowledge generation, all intra-entity relationships (e.g., parent-child relationships between organizations) and inter-entity relationships (e.g., a member has a certain skill, that certain skill is needed by a job) in the Knowledge Graph are computed by state-of-the-art artificial intelligence methods and, when necessary, verified by domain experts. To extend the comprehensiveness of LinkedIn data, external data sources are ingested and integrated into the LinkedIn Knowledge Graph.
In the following, we discuss three LinkedIn strategies for enriching data value from the perspective of the Knowledge Graph.
Structured Data on top of Entity Taxonomies
LinkedIn data is semi-structured, as shown in the below member profile example. It consists of structured attributes (including image, name, position, organization, geography and company size) and unstructured attributes in the form of the profile summary written in free text. We use machine learning techniques to extract skills, years of experience and other relevant organizations from the profile summary. Then, all structured and extracted attributes are mapped to standardized entities so that this LinkedIn member (“Deepak Agarwal”) can be represented by a set of entity identifiers.
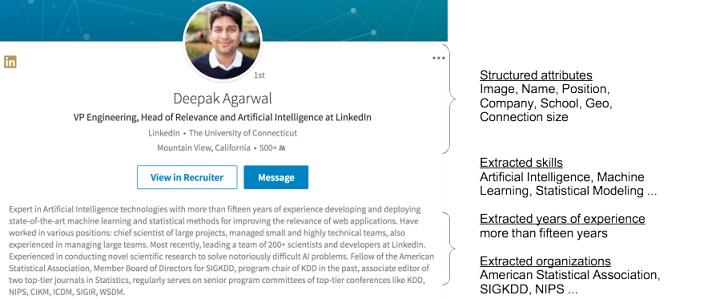
This process of standardization is the foundation of the LinkedIn Knowledge Graph, where various kinds of content are tagged explicitly by identifiers without ambiguity. Equipped with it, applications can search and recommend content with a clear intent, and organize and display content in rich results, both of which increase user engagement and revenue.
Data-Sharing Platform as Single Source of Truth
The global identifier scheme allows for knowledge sharing across the entire LinkedIn ecosystem. We build a data-sharing platform as the single source truth to generate and serve the Knowledge Graph. For example, Ads Targeting and People Search both consume data from the same platform. Given a title (“Software Engineer”), the set of LinkedIn members targeted by Ads is the same as the set of LinkedIn members returned by the search engine.
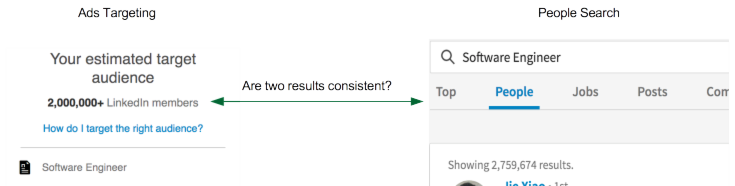
Sharing knowledge across different applications can significantly reduce the duplicated engineering work needed by different applications, and conveniently unifies company-wide data analytics and insight generation.
Bring Value to Our Members
Not only has the Knowledge Graph driven a disproportionate share of total LinkedIn monetization value (e.g., members with high-quality, standardized profiles are more valuable than members with little or poorly-structured profile information), but it also brings unique value back to our members. For example, LinkedIn auto-generates a personalized profile summary based on professional entities inferred by the Knowledge Graph, and recommends it to members who don’t have completely standardized profiles.

LinkedIn also leverages the Knowledge Graph to generate suggested additions to member profiles, e.g., “peers with this skill receive 30% more messages” or “peers with this skill have a 15% higher chance of getting a new job.”
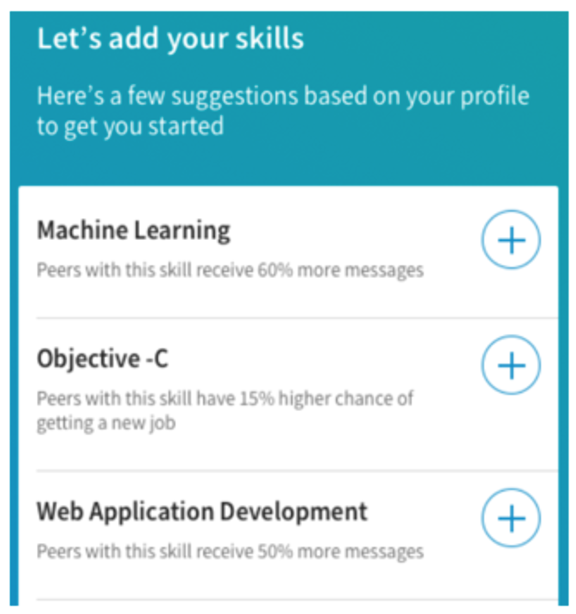
In both examples, the LinkedIn Knowledge Graph brings value to our members by interactively engaging them to complete their profiles. The collected user feedback (“accept,” “decline,” “ignore”) in turn reinforces the learning of the Knowledge Graph, creating a robust LinkedIn data ecosystem.
 Contributed by: Qi He, Senior Engineering Manager – Machine Learning & Data Mining, Head of Data Standardization at LinkedIn. In his role, he leads a team of machine learning scientists and software engineers to help LinkedIn realize its vision of creating economic opportunities through building the world’s best universal knowledge base for entities. Bee-Chung Chen, a Principal Staff Engineer & Applied Researcher at LinkedIn. Prior to joining the company in 2012, he spent four years as a research scientist at Yahoo. He was also previous at research assistant at the University of Wisconsin-Madison.
Contributed by: Qi He, Senior Engineering Manager – Machine Learning & Data Mining, Head of Data Standardization at LinkedIn. In his role, he leads a team of machine learning scientists and software engineers to help LinkedIn realize its vision of creating economic opportunities through building the world’s best universal knowledge base for entities. Bee-Chung Chen, a Principal Staff Engineer & Applied Researcher at LinkedIn. Prior to joining the company in 2012, he spent four years as a research scientist at Yahoo. He was also previous at research assistant at the University of Wisconsin-Madison.

Sign up for the free insideAI News newsletter.



Speak Your Mind