NVIDIA Extends Lead on MLPerf Benchmark with A100 Delivering up to 237x Faster AI Inference Than CPUs, Enabling Businesses to Move AI from Research to Production
NVIDIA today announced its AI computing platform has again smashed performance records in the latest round of MLPerf, extending its lead on the industry’s only independent benchmark measuring AI performance of hardware, software and services.
NVIDIA won every test across all six application areas for data center and edge computing systems in the second version of MLPerf Inference. The tests expand beyond the original two for computer vision to include four covering the fastest-growing areas in AI: recommendation systems, natural language understanding, speech recognition and medical imaging.

Organizations across a wide range of industries are already tapping into the NVIDIA A100 GPU’s exceptional inference performance to take AI from their research groups into daily operations. Financial institutions are using conversational AI to answer customer questions faster; retailers are using AI to keep shelves stocked; and healthcare providers are using AI to analyze millions of medical images to more accurately identify disease and help save lives.
“We’re at a tipping point as every industry seeks better ways to apply AI to offer new services and grow their business,” said Ian Buck, general manager and vice president of Accelerated Computing at NVIDIA. “The work we’ve done to achieve these results on MLPerf gives companies a new level of AI performance to improve our everyday lives.”
The latest MLPerf results come as NVIDIA’s footprint for AI inference has grown dramatically. Five years ago, only a handful of leading high-tech companies used GPUs for inference. Now, with NVIDIA’s AI platform available through every major cloud and data center infrastructure provider, companies representing a wide array of industries are using its AI inference platform to improve their business operations and offer additional services.
Additionally, for the first time, NVIDIA GPUs now offer more AI inference capacity in the public cloud than CPUs. Total cloud AI inference compute capacity on NVIDIA GPUs has been growing roughly 10x every two years.
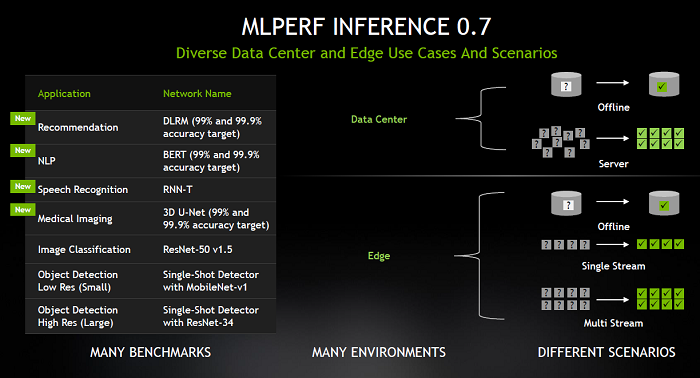
NVIDIA Takes AI Inference to New Heights
NVIDIA and its partners submitted their MLPerf 0.7 results using NVIDIA’s acceleration platform, which includes NVIDIA data center GPUs, edge AI accelerators and NVIDIA optimized software.
NVIDIA A100, introduced earlier this year and featuring third-generation Tensor Cores and Multi Instance GPU technology, increased its lead on the ResNet-50 test, beating CPU-only systems by 30x versus 6x in the last round. Additionally, A100 outperformed the latest available CPUs by up to 237x in the newly added recommender test for data center inference, according to the MLPerf Inference 0.7 benchmarks.
This means a single DGX A100 server can provide the same performance as 950 dual-socket CPU servers, offering customers extreme cost efficiency when taking their AI recommender models from research to production.
The benchmarks also show that NVIDIA T4 Tensor Core GPU continues to be a solid inference platform for mainstream enterprise, edge servers and cost-effective cloud instances. NVIDIA T4 GPUs beat CPUs by up to 28x in the same tests. In addition, the NVIDIA Jetson AGX Xavier is the performance leader among SoC-based edge devices.
Achieving these results required a highly optimized software stack including NVIDIA TensorRT inference optimizer and NVIDIA Triton inference serving software, both available on NGC, NVIDIA’s software catalog.
In addition to NVIDIA’s own submissions, 11 NVIDIA partners submitted a total of 1,029 results using NVIDIA GPUs, representing over 85 percent of the total submissions in the data center and edge categories.
Sign up for the free insideAI News newsletter.



Speak Your Mind