
There’s good reason why the word “modern” is in the title of this new title from CRC Press: “Modern Data Science with R, 2nd,” by 3 professors Benjamin S. Baumer, Daniel T. Kaplan, and Nicholas J. Horton – the goal of the text is to provide a solid guide for state-of-the-art data science with the R language. It achieves this goal masterfully. The entire book is loaded with well-crafted and “modern” code based on the tidyverse, the suite of packages developed by industry guru Hadley Wickham to bring R into the modern era. Many data scientists have adopted the ways of the tidyverse as their foundation for coding data science problems. The coding style presented in the book is top-rate; in fact, if you’re looking for a coding style to mimic, I say following the author’s ways of coding would lead you down a good path (impress your GitHub followers this way). Here is an example of some “modern” R code found in the book:

Before digging into the chapters, let me just say that this book is produced in a high very quality manner. The hardcover textbook is put together in an excellent way: solid binding, quality paper stock, and beautiful use of color throughout. It’s a quality product, so kudos to the publisher. Weighing in at nearly 5 lbs., with 21 chapters, and 631 pages, this book is serious in delivering a long-lasting addition to your professional library. It already occupies a space on my crowded work desk.
The coverage of the subject “data science” is excellent. Part I “Introduction to Data Science” gets you started with topics like data visualization, data wrangling, tidy data, vectorized operations. I greatly appreciated Chapter 8 that concludes Part I – “Data science ethics,” as I always advise my students it is important to use their new data science “superpowers” in an ethical way.
Part II provides a very useful treatment of statistics and modeling, going over statistical foundations and predictive modeling. This section also includes content for supervised and unsupervised machine learning, and simulation.
Part III presents a number of topics in data science: dynamic and customize data graphics, SQL and database administration. I loved Chapters 17 and 18 on working with geospatial data which is very hot right now. The section is rounded out with discussions of text analytics (regular expressions), network science, and big data.
Part IV contains a series of appendices describing the special R package developed for the book (MDSR), along with Appendix E on regression modeling (not sure why it wasn’t included in Chapter 11 on supervised learning).
Another aspect of the book that I really appreciated was its thoughtful use of data sets for coding examples (the MDSR R package is available for accessing the data sets). It’s as-if every example had a well-conceived data set and use case. This means that you can easily extend the examples found in the book to your own real-life problems. Nice touch!
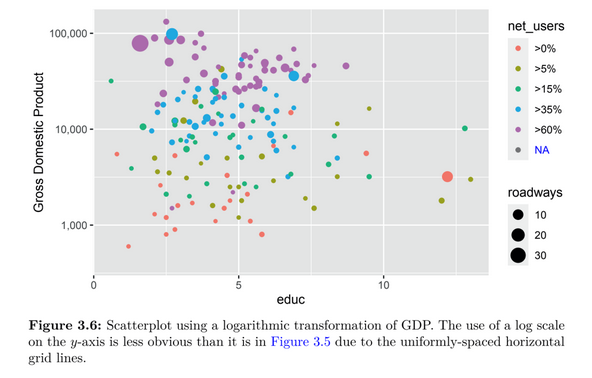
Here is an example of the high-quality data visualizations found in the book:
I’ve already recommended this book to my Intro to Data Science students as a great way to continue learning data science using R.

Contributed by Daniel D. Gutierrez, Editor-in-Chief and Resident Data Scientist for insideAI News. In addition to being a tech journalist, Daniel also is a consultant in data scientist, author, educator and sits on a number of advisory boards for various start-up companies.
Sign up for the free insideAI News newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind